2019.03.25 SSU
1. PaDEL
PaDEL使用方法:PaDEL產生的1D/2D資料要注意:
含以下兩個非認定字元:(#Name?、Infinity),在進行資料分析時須先拿掉。可用excel取代字元,或於weka中進行兩步驟filter去除。
weka兩步驟filter方法如下:
| (1) | weka.filters.unsupervised.attribute.RemoveType | 能以此移除string |
| (2) | weka.filters.unsupervised.attribute.NumericCleaner ✩然後要在minDefault處打上NaN |
能以此移除NaN缺失值 |
2. RDKit
基本需要每一種fingerprint各一個RDKit Fingerprint + Expand Bit Vector,於Fingerprint type改fingerprint的類型,所以當要產生多種Fingerprint種類時需要拉大量重複的兩個node接在一起((KNIME參照"KNIME_20190121_Fingerprint_BBB"的protocol))
3. Data資料處理
利用SMOTE、SpreadSubsample達到資料平衡:• SMOTE: 利用少數類別中的點,及其鄰近的5個點連線,隨機於線性中生成新的數據
• SpreadSubsample: 以隨機減少多數類別的數量來達成少數類別與多數類別間的平衡
使用以下:
| weka.filters.unsupervised.instance.SMOTE | 要調整percentage 數字為 [(多數量/少數量)-1] |
| weka.filters.unsupervised.instance.SpreadSubsample | 要調整distributionSpread從0.0->1.0 1.0是讓多的往少的數量降 |
另外:切割資料(Cut1、Cut2)是於excel中進行,以"=RAND()"函數產生亂數,隨機挑選36個no(n),109個yes(p)於Cut2做獨立測試用,其他留於Cut1做model建立
4. Weka ML
• RandomForest• SGD (SGD introduction)
另:SimpleCLI=>點此
如使用Weka-KnowledgeFlow
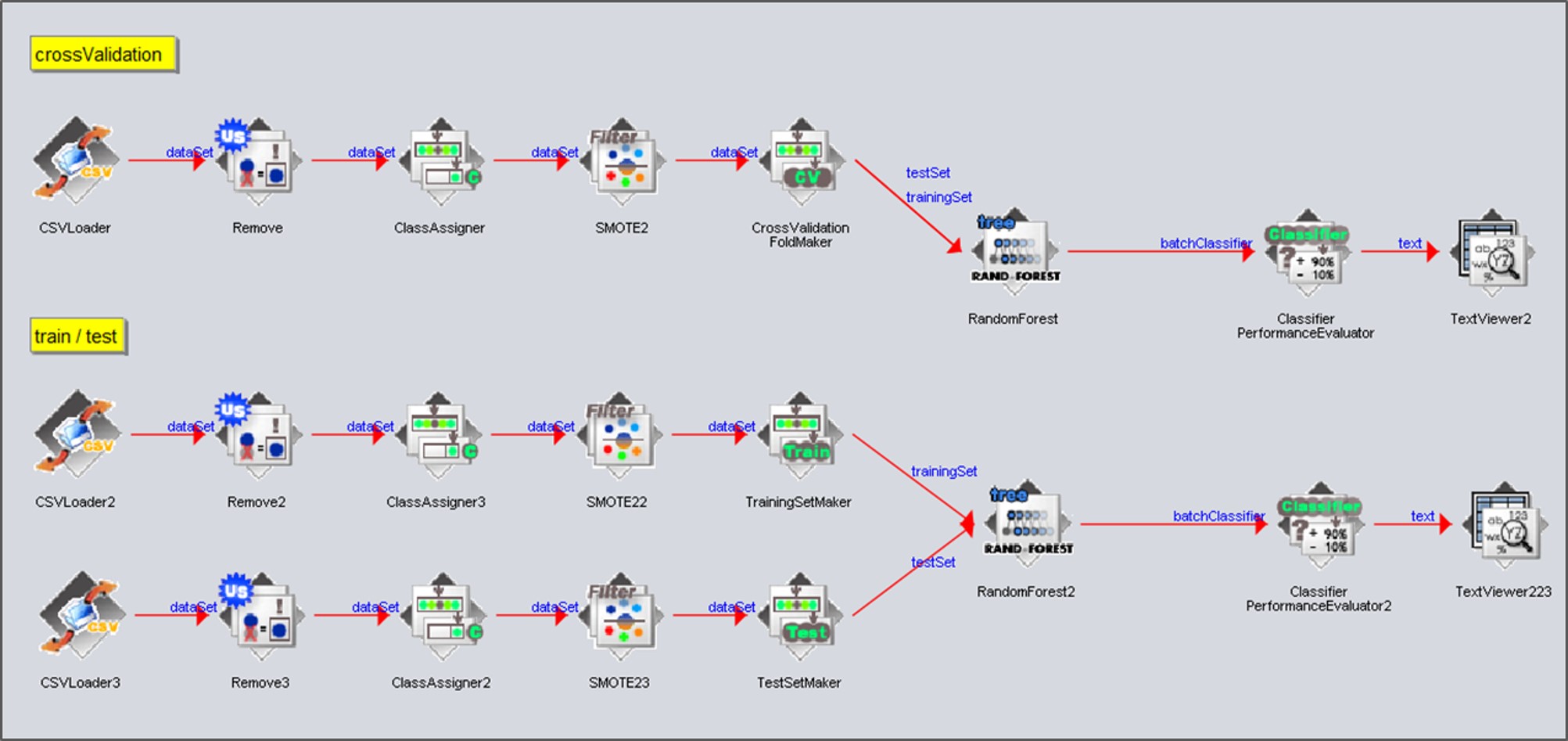 ((Weka參照"20190408_Weka-Flow_BBB_training-test.kf"的protocol))
((Weka參照"20190408_Weka-Flow_BBB_training-test.kf"的protocol))
5. AutoWeka
位於weka介面的最右,可以precision、fMeasure、areaUnderROC等等的作為比對條件(一次一個)如使用Weka-KnowledgeFlow
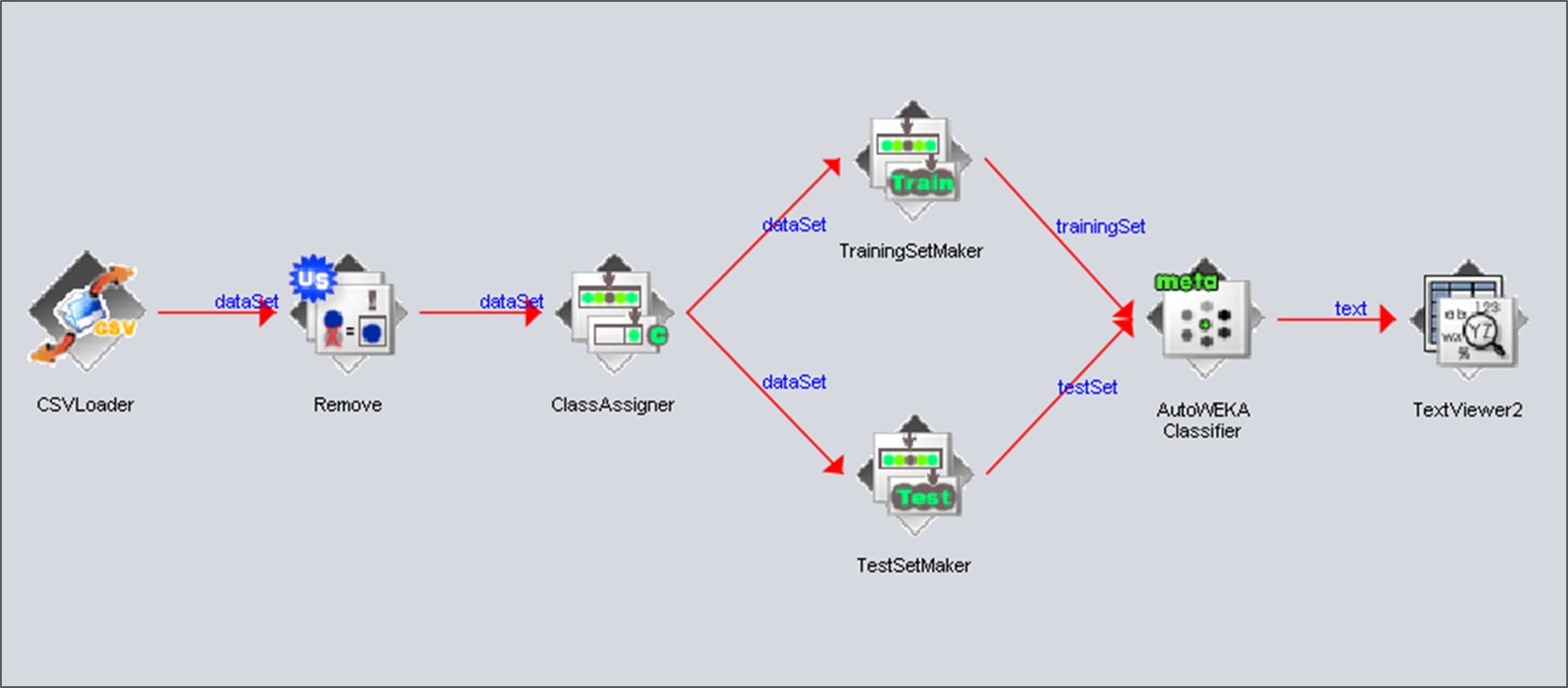 ((Weka參照"20190409_Weka-Flow_BBB_autoweka.kf"的protocol))
((Weka參照"20190409_Weka-Flow_BBB_autoweka.kf"的protocol))
6. Deep learning
cross validation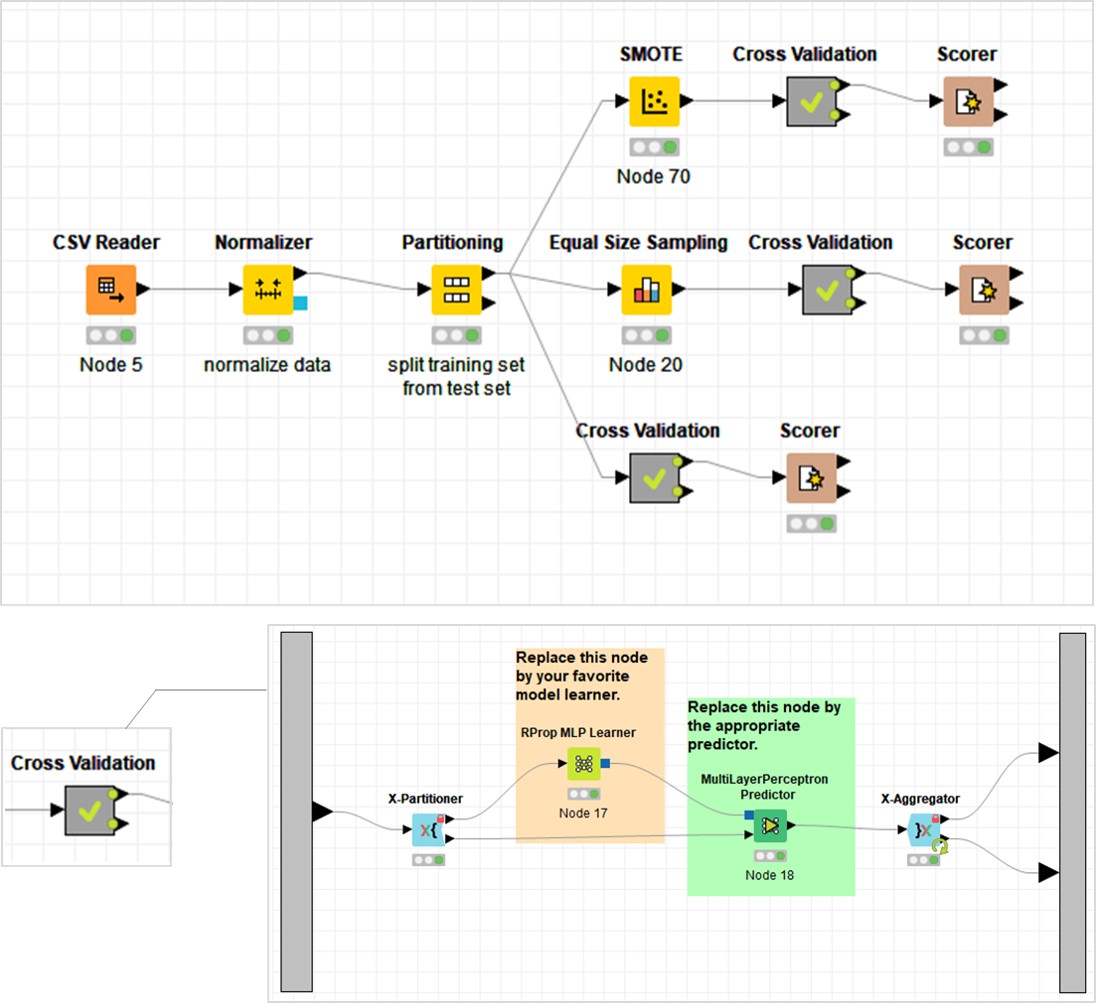 ((KNIME參照"KNIME_DL_20190213_MLP_deep-learning_BBB_update2"的protocol))
((KNIME參照"KNIME_DL_20190213_MLP_deep-learning_BBB_update2"的protocol))當要測試training set cross validation及test set的結果
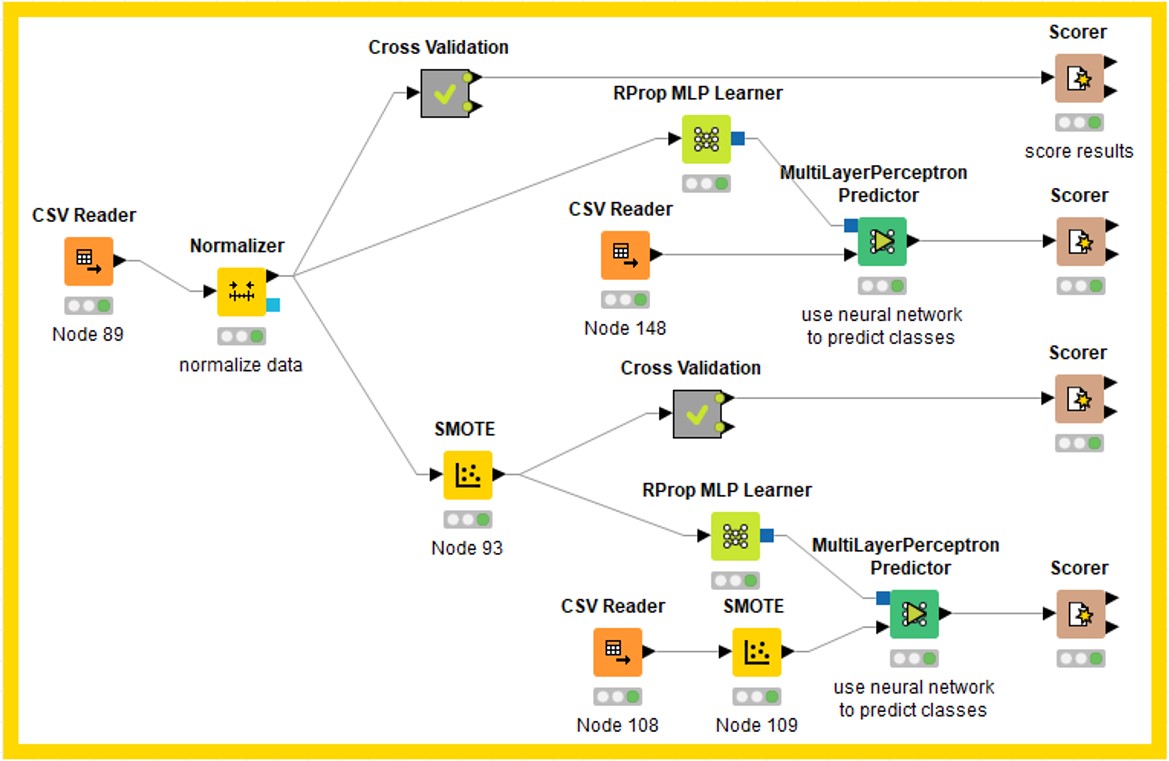 ((KNIME參照"KNIME_DL_20190328_MLP_deep-learning"的protocol))
((KNIME參照"KNIME_DL_20190328_MLP_deep-learning"的protocol))MLP參數調整:Maximum number of iterations、Number of hidden layers(層數)、Number of hidden neurons per layer(每層節點數)
SimpleMLP/DeepMLP
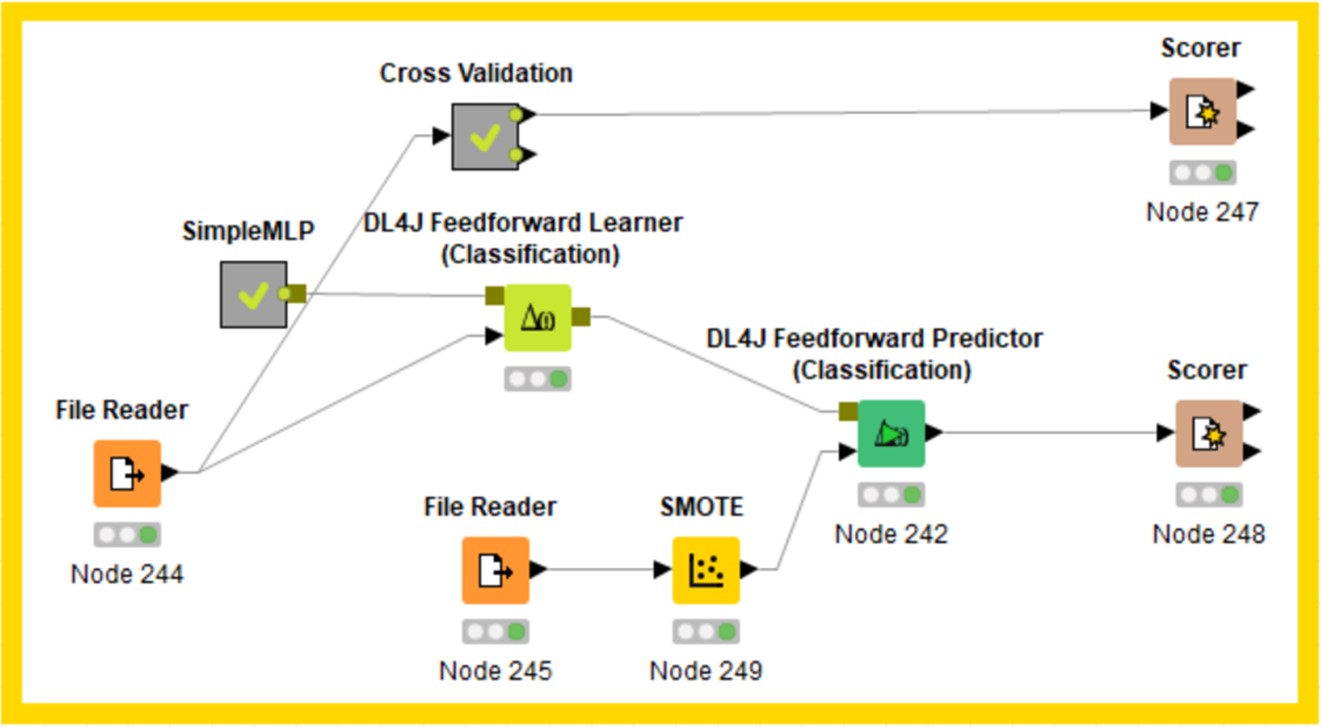
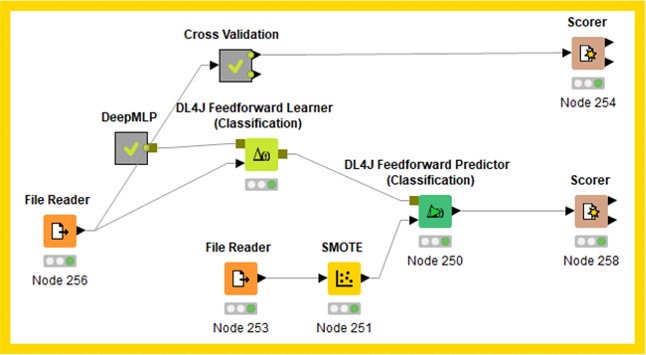 ((KNIME參照"KNIME_DL_20190329_MLP_SimpleMLP-DeepMLP"的protocol))
((KNIME參照"KNIME_DL_20190329_MLP_SimpleMLP-DeepMLP"的protocol))會用到SGD參數,需調learning rate、batch size、Epochs (可參考SGD introduction的說明)
※KNIME的SMOTE的node記得要選取: ⦿ Oversample monority classes